Deploy A Custom Text Encoder Model
This guide helps you deploy the BERT model with Hyperpod AI and perform an inference through a simple API.
🚀 RECOMMENDED: Try our ready-made Colab notebook — run everything in your browser with zero hassle!
🤖 What is BERT?
BERT (Bidirectional Encoder Representations from Transformers) is a groundbreaking natural language processing model developed by Google AI. It understands language context by analyzing text in both directions, enabling it to excel at a wide range of tasks like sentiment analysis, question answering, and document classification.
To use BERT, we first tokenize text—converting words and sentences into numerical representations that the model can process. BERT then generates rich contextual embeddings, which can be leveraged for downstream NLP tasks or further fine-tuned for specific applications.
🚀 Step 1: Downloading the model
In this tutorial we will be using the BERT model. Download the sample model using this link, as well as the sample data for later use.
🔐 Step 2: Sign Up on Hyperpod AI
Head to app.hyperpodai.com
- Create a free account (includes 10 free hours)
- Click on “Upload your Model”
🛠️ Step 3: Set Up Your Project
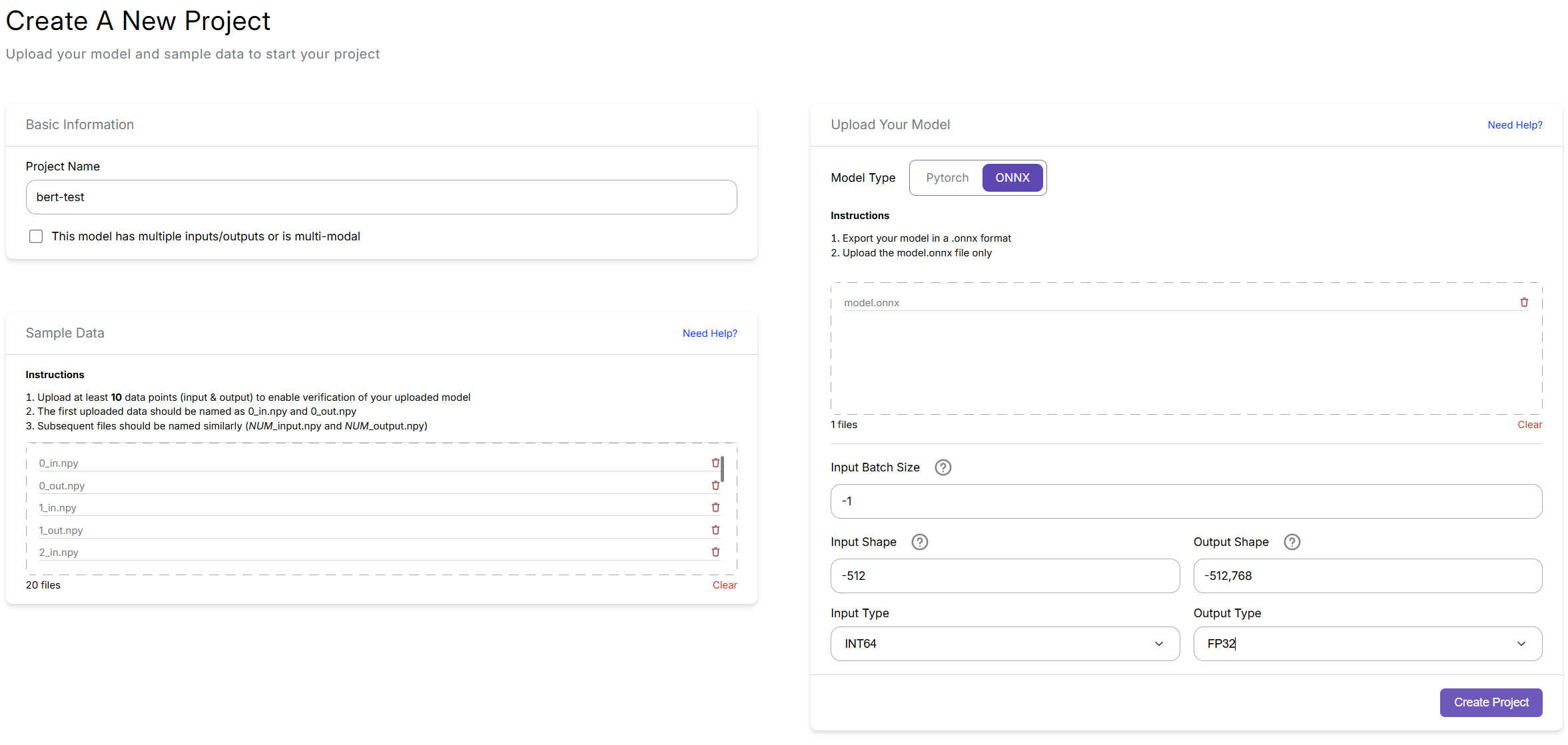
Fill in the project form as follows:
-
Project Name: (Any name — for your reference)
-
Upload Your Model: Upload the ONNX model file you downloaded
-
Model Type:
ONNX -
Input Batch Size:
-1Batch size controls how many samples are processed at once. Note that in this setup, positive values indicate a fixed batch size, while negative values allow dynamic batching up to the specified maximum.
-
Input Shape:
-512The model expects input sequences up to 512 tokens (maximum context length), with a flexible batch dimension.
-
Output Shape:
-512,768The model outputs an embedding of shape
[-512, 768]. -
Input Type:
INT64 -
Output Type:
FP32 -
Sample Data
- Allows the platform to validate your model’s inputs and outputs, optimizing deployment.
- Upload the sample_data you downloaded earlier (e.g., tokenized input arrays in
.npyformat). - Trying to genereate your own sample data? See the guide to creating sample inputs.
✅ Your setup should look like this:
- Click Create Project. This may take a few minutes as Hyperpod sets up and optimizes the deployment for you automatically.
🔑 Step 4: Set up your API
-
After the deployment is done it should look like something this

-
Go to Deployment
-
You can choose between Test mode and Production mode. For this guide, select Test mode — it’s the most cost-effective option. Read more about the difference between test and production mode.
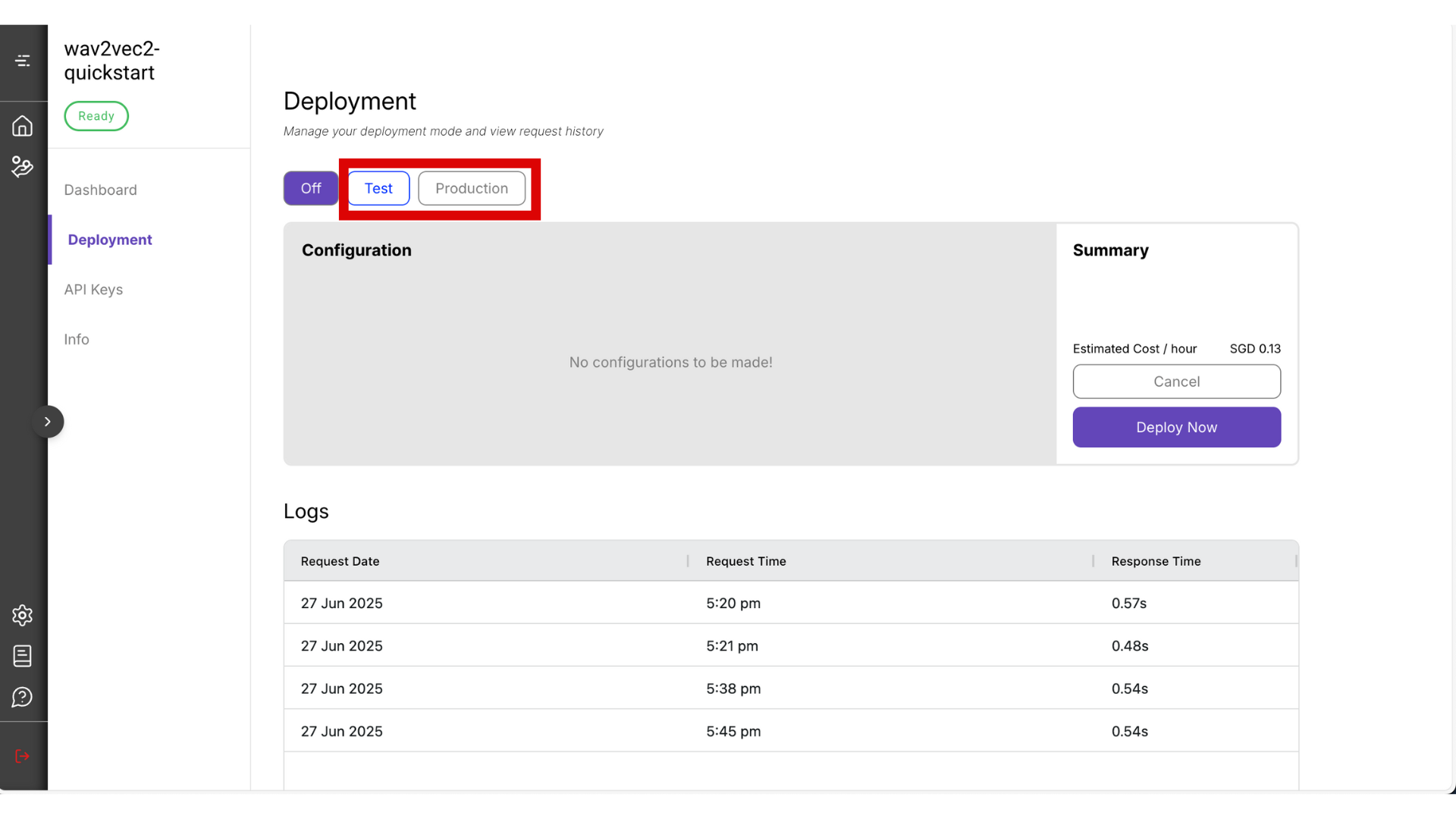
⚠️ Warning: Be sure to manually turn it off by clicking the Off button when you’re not using it, to avoid unnecessary charges.
-
The deployment process may take around 10 minutes. Once it’s ready, copy the Endpoint URL and Project ID that will be visible from this page.
-
Navigate to the API Keys section.
- Set a name (for your own reference), and choose a validity period. Then click Create Key
- After the key is generated, copy and store it somewhere safe — you won’t be able to view it again from the platform.
⚠️ Warning: Never store your API key in public locations (like GitHub repositories). If exposed, malicious users could access your API and incur charges on your behalf.
✅ Final Step: Call the API
To generate inputs, you’ll need to first tokenize your text using the Huggingface BertTokenizer tool:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "Hello, this is a sample sentence for BERT!"
inputs = tokenizer(
text,
padding='max_length',
truncation=True,
max_length=32,
return_tensors="pt"
)
input_arr = inputs['input_ids']
input_arr.dtype
input_arr.numpy().shape
Now that you have the tokenized text array, send it to the inference endpoint:
import httpx
client = httpx.Client(http2=True, timeout=httpx.Timeout(30.0))
endpoint_url = 'your-endpoint-url'
api_key = 'your-api-key'
project_id = 'your-project-id'
payload = {
"project_id": project_id,
"grpc_data": {
"array": input_arr.numpy().tolist(),
"dtype": "int64"
}
}
response = client.post(
endpoint_url,
headers={'content-type': 'application/json', 'x-api-key': api_key},
json=payload
)
print(response.text)
predicted = response.json()["array"][0] # use your label dictionary to identify what this label is